Recently, I've been digging deeper into how large language models (LLMs) actually work, including their underlying mechanism: transformers. Inside the transformer paper? , there is a single word that caught my eye: Attention. This "Attention" word is special because it does not look like technical jargon—it's just an English word; there is no inherent technical meaning to it. In my field (software engineering), the jargons are much more specialized. As an example, we have latency, scalability, idempotence, and immutability. I don't think anyone would ever use those fancy words in a real and normal conversation. But "Attention", that's a common word that's well used in an everyday conversation. Since it's a normal-sounding word, it's hard to get the actual, intuitive sense of the meaning in terms of its technical machine learning usage. I want to visit my favourite online dictionary to understand the common usage:
, there is a single word that caught my eye: Attention. This "Attention" word is special because it does not look like technical jargon—it's just an English word; there is no inherent technical meaning to it. In my field (software engineering), the jargons are much more specialized. As an example, we have latency, scalability, idempotence, and immutability. I don't think anyone would ever use those fancy words in a real and normal conversation. But "Attention", that's a common word that's well used in an everyday conversation. Since it's a normal-sounding word, it's hard to get the actual, intuitive sense of the meaning in terms of its technical machine learning usage. I want to visit my favourite online dictionary to understand the common usage:
"May I have your attention please?" When you ask that question, you are asking people to focus their mental powers on you. Whether they do or not depends on your next words. You'll have their full attention if you say, "Here's $100."
The semantic meaning in conversation is easy enough to understand. Then, what does it have to do with LLM? Specifically, what makes this word special enough to become the first word of the transformer paper—Attention is all you need? Well, one way to find out is to read it.
In the paper? , the word "attention" appears 84 times, including four references:
, the word "attention" appears 84 times, including four references:
- Yoon Kim, Carl Denton, Luong Hoang, and Alexander M. Rush. Structured attention networks. In International Conference on Learning Representations, 2017.
- Samy Bengio, Łukasz Kaiser. Can active memory replace attention? In Advances in Neural Information Processing Systems (NIPS), 2016.
- Minh-Thang Luong, Hieu Pham, and Christopher D. Manning. Effective approaches to attention-based neural machine translation. arXiv preprint arXiv:1508.04025, 2015.
- Ankur Parikh, Oscar Täckström, Dipanjan Das, and Jakob Uszkoreit. A decomposable attention model. In Empirical Methods in Natural Language Processing, 2016.
Among all of these references, the paper by Luong et al., 2015? is written in 2015, the oldest of them all. This passage is taken from its introduction where it firstly mentions attention:
is written in 2015, the oldest of them all. This passage is taken from its introduction where it firstly mentions attention:
In parallel, the concept of “attention” has gained popularity recently in training neural networks, allowing models to learn alignments between different modalities
I don't think the paper explains the actual meaning of the term "attention" on its own. It explains that "attention" allows the model to learn better. But what is "attention"? This is the main question that I'm trying to find the answer to. The meaning of the word itself, not in relation to something else. Whenever attention is mentioned in the paper, it keeps being explained as either a mechanism, an architecture, or a model without any intuitive understanding of the actual word. This is probably by design; machine learning researchers have probably found the word "attention" to be so common that it doesn't need any specific explanation at all. Let me first go back to the transformer paper:
Attention mechanisms have become an integral part of compelling sequence modeling and transduction models in various tasks, allowing modeling of dependencies without regard to their distance in the input or output sequences [2, 16]. In all but a few cases [22], however, such attention mechanisms are used in conjunction with a recurrent network.
The paper mentions about attention but it's still a non-explanatory introduction. There are two ways I can go with this exploration: I'll keep digging until I found a clear-cut meaning of the word in the scope of machine learning or just accept this non-explanatory explanation and focus on the transformer paper, of which I may derive my own understanding of the word myself. I'm choosing the latter since I already have a decent understanding of the word in terms of linguistic conversational usage, and I can bridge it to the machine learning usage by seeing how it's actually used in the transformer paper?. I would quote what I think is the best summarization of this paper:
In this work we propose the Transformer, a model architecture eschewing?recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output.
I highlighted the word "eschewing" because this word implies the major contribution of transformer is the usage of attention in place of recurrence. The previously quoted (Luong et al., 2015?) paper is indeed using recurrent neural network (RNN? ) as its main network architecture. In the abstract, the transformer paper also mentioned it also avoid using convolutions, which I assume referring to the convolutional neural network (CNN?
) as its main network architecture. In the abstract, the transformer paper also mentioned it also avoid using convolutions, which I assume referring to the convolutional neural network (CNN? ). So, I got the main idea of transformer: no to RNN, no to CNN, yes to attention. This main idea is still not explaining what attention is in itself, but its existence is justifiable by eliminating RNN (sequential—processing tokens in order) and CNN (looking at small pieces at a time) in the transformer architecture.
). So, I got the main idea of transformer: no to RNN, no to CNN, yes to attention. This main idea is still not explaining what attention is in itself, but its existence is justifiable by eliminating RNN (sequential—processing tokens in order) and CNN (looking at small pieces at a time) in the transformer architecture.
I'm getting increasingly close to digging into the mathematical explanation of Attention at this point—the Query-Key-Value model—but choose not to since it's not the focus of this article. So, ultimately, I did what a normal human would do: I went to Google?Yes, I probably can just use chatbots, but I'm interested in exploring answers to a query, not the answer in itself. search using "attention using rnn" query, scrolling some results, and I ended up in a stackoverflow thread from 2020? , which then brings me to a very specific stackoverflow?I miss the days where stackoverflow is still active. It's not the best place to have a question, but repeatedly talking to a robot for my queries make me miss a real human conversation. tag: attention-model?
, which then brings me to a very specific stackoverflow?I miss the days where stackoverflow is still active. It's not the best place to have a question, but repeatedly talking to a robot for my queries make me miss a real human conversation. tag: attention-model? . It's not a very active tag, but I don't have better options. Since my goal is to understand Attention intuitively, I need a history lesson, so I pressed the last page of that tag, and found about a specific keyword that seems to come out often:
. It's not a very active tag, but I don't have better options. Since my goal is to understand Attention intuitively, I need a history lesson, so I pressed the last page of that tag, and found about a specific keyword that seems to come out often: seq2seq from tensorflow. I looked it up? , and it ultimately brings me back to the Luong et al., 2015? paper:
, and it ultimately brings me back to the Luong et al., 2015? paper:
This tutorial demonstrates how to train a sequence-to-sequence (seq2seq) model for Spanish-to-English translation roughly based on Effective Approaches to Attention-based Neural Machine Translation (Luong et al., 2015). While this architecture is somewhat outdated, it is still a very useful project to work through to get a deeper understanding of sequence-to-sequence models and attention mechanisms (before going on to Transformers).
Interesting! The general idea of that paper is the implementation of attentional mechanism to translate text using RNN. The paper introduces two general architecture: Global and Local attention.
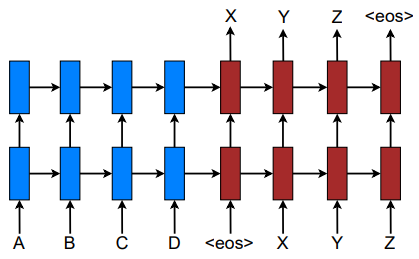
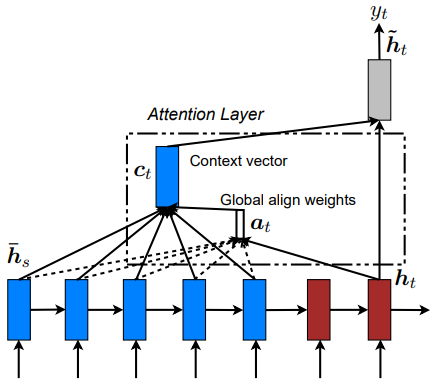
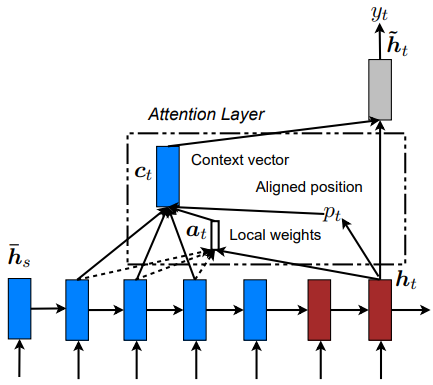
The seq2seq model is using an encoder-decoder?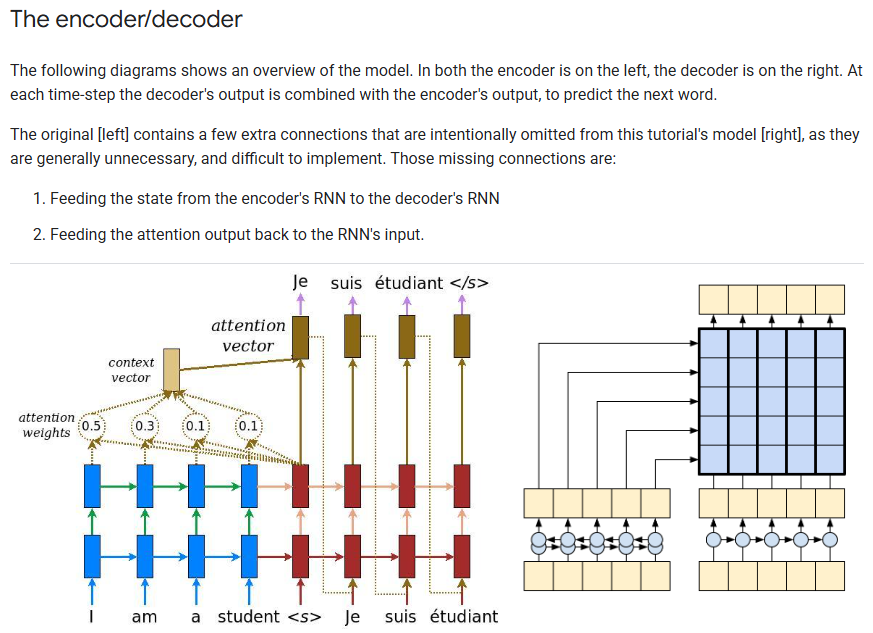 approach; the blue ones are there to express the encoding phase, while the red ones are for expressing the decoding phase. Figures 2 and 3 represent the global and local approaches of the attention mechanism for translating text, respectively. The global/local difference is akin to when I open my eyes whole vs when I squint my eyes to focus on to something. If I want to have a full picture of my surroundings, I open my eyes—my senses—to feel the whole surrounding area. If I want to focus on a specific part of the environment, I would use my eyes to stare at that point, and my brain will automatically filter unimportant informations unrelated to the thing that I want to focus on. I don't think the metaphor perfectly encapsulates the meaning that the author intends to convey, so I'd like to quote the explanation, which I'm happy to say is a well-articulated one:
approach; the blue ones are there to express the encoding phase, while the red ones are for expressing the decoding phase. Figures 2 and 3 represent the global and local approaches of the attention mechanism for translating text, respectively. The global/local difference is akin to when I open my eyes whole vs when I squint my eyes to focus on to something. If I want to have a full picture of my surroundings, I open my eyes—my senses—to feel the whole surrounding area. If I want to focus on a specific part of the environment, I would use my eyes to stare at that point, and my brain will automatically filter unimportant informations unrelated to the thing that I want to focus on. I don't think the metaphor perfectly encapsulates the meaning that the author intends to convey, so I'd like to quote the explanation, which I'm happy to say is a well-articulated one:
a global approach in which all source words are attended and a local one whereby only a subset of source words are considered at a time.
I love this explanation. Let me rephrase by saying global attention approach of a translation function is when the whole paragraph, the whole chunk of texts—can even be the whole book where the word is sourced from—are considered to get its semantic meaning while local attention is much more focused to just a few neighboring words. Intuitively, I can also say that the global attention function calculation is much more expensive than the local ones; basically a trade-off between resource (time, compute) and quality.
Now, I want to see if I can apply this intuitive understanding of Attention to something that is more familiar: AI-assisted programming. For this example, I would initiate a conversation to a chatbot that uses LLM—transformer—as its main driver. Let's try making a simple python script to handle a POST request. I'm using this query to initiate the conversation to the chatbot:
"create a python post request handler of a login form"
A very simple and straightforward query (or prompt). The full response is available in my public github gist? . The result is okay at the first glance, but I noticed something. I asked for a simple backend code, but the chatbot added a security-related text in its response unprompted. To verify whether the code is secure, I have to actually read it and check. But for this experiment, I'm going to pass the result to another chatbot instance with an added keywords of security-related text. The new query is also simple:
. The result is okay at the first glance, but I noticed something. I asked for a simple backend code, but the chatbot added a security-related text in its response unprompted. To verify whether the code is secure, I have to actually read it and check. But for this experiment, I'm going to pass the result to another chatbot instance with an added keywords of security-related text. The new query is also simple: how secure is this code plus the previously generated code.
The result is saved in my other public github gist?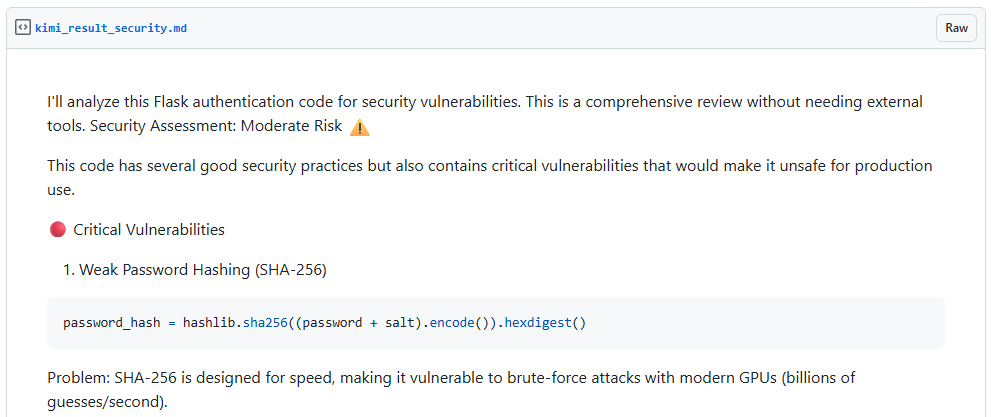 . Now, I'm going to do a simple manual review of the generated text and see if it can show me tell me whether the first generated text—the initial python script—is implemented with, in its own words, "security best practices."
. Now, I'm going to do a simple manual review of the generated text and see if it can show me tell me whether the first generated text—the initial python script—is implemented with, in its own words, "security best practices."
The first vulnerability is the usage of SHA256 for password hashing. I agree because argon2 or bcrypt is a standard practice for hashing a password due to its slowness—Yes, password hash computation need to be computationally slow? . The next one is a possible timing attack. Frankly, this is a TIL?Today I learned moment for me. I knew about the existence of timing-based attacks, but I couldn't quite understand it until I see this example:
. The next one is a possible timing attack. Frankly, this is a TIL?Today I learned moment for me. I knew about the existence of timing-based attacks, but I couldn't quite understand it until I see this example:
return hash_obj.hexdigest() == stored_hash
The above code is problematic because the equality string comparison will return as soon as it finds a mismatch. Therefore, theoretically, an attacker can enumerate a password hash by guessing and observing its timing result (a better implementation is available on my GitHub gist above). The last critical vulnerability is a hardcoded demo credentials, let's see the actual generated code about this:
# Simulated user database (in production, use proper database)
# Passwords should be stored as properly salted hashes
USERS_DB = {
'admin': {
'password_hash': hashlib.sha256('admin123'.encode()).hexdigest(), # Demo only - use bcrypt in production
'salt': 'random_salt_here',
'role': 'admin',
'active': True
},
'user': {
'password_hash': hashlib.sha256('user123'.encode()).hexdigest(),
'salt': 'another_salt',
'role': 'user',
'active': True
}
}
I have mixed feelings here. There is a comment, sure, but this comment will only be useful for anyone who understands what it means. If the whole script is copied-pasted directly, there is a chance that this part of the code may never be deleted. This may also be a limitation of a web-based AI-assisted programming; they may have a tendency to generate a single file text. To also be fair to the chatbot, bcrypt is also mentioned in the comment, but I would also argue that the implementation itself should be in bcrypt by default. Let me stop here with the code review since this is not the main intention of this article, so let's go back to Attention.
In my second query, I added a security-related text, and the resulted text is focused on the initial code's security aspect. People are saying this is "prompt engineering", and yes, in a way, it is, but I would also say this is a direct implementation of how attention works in practice. The attentional mechanism of the transformer guides the resulting text to lean towards generating security-related answers, which is very obvious at this point, since the whole "prompt engineering" niche is about guiding the result by adding a more related text to the query (prompt), but it's very interesting to know that Attention is the main driver of it! :)